Note to reader
I do not include large code snippets as this was an assignment for my deep learning course at Northwestern and I don’t want future students copying it. It exists in a private repo of mine containing my school assignments. I will try to do my best to illustrate the work I did with fewer code examples
Github Link
- Private url
Overview
This assignment challenged us to learn more about sequence modeling, and better understand the conceptual pros/cons between RNNs and LSTMs. We implemented RNNs, LSTMs, and a deep reinforcement learning model to play pong. I find that the sequence modeling and autoencoder information is more interesting in this project, so I didn’t include it here.
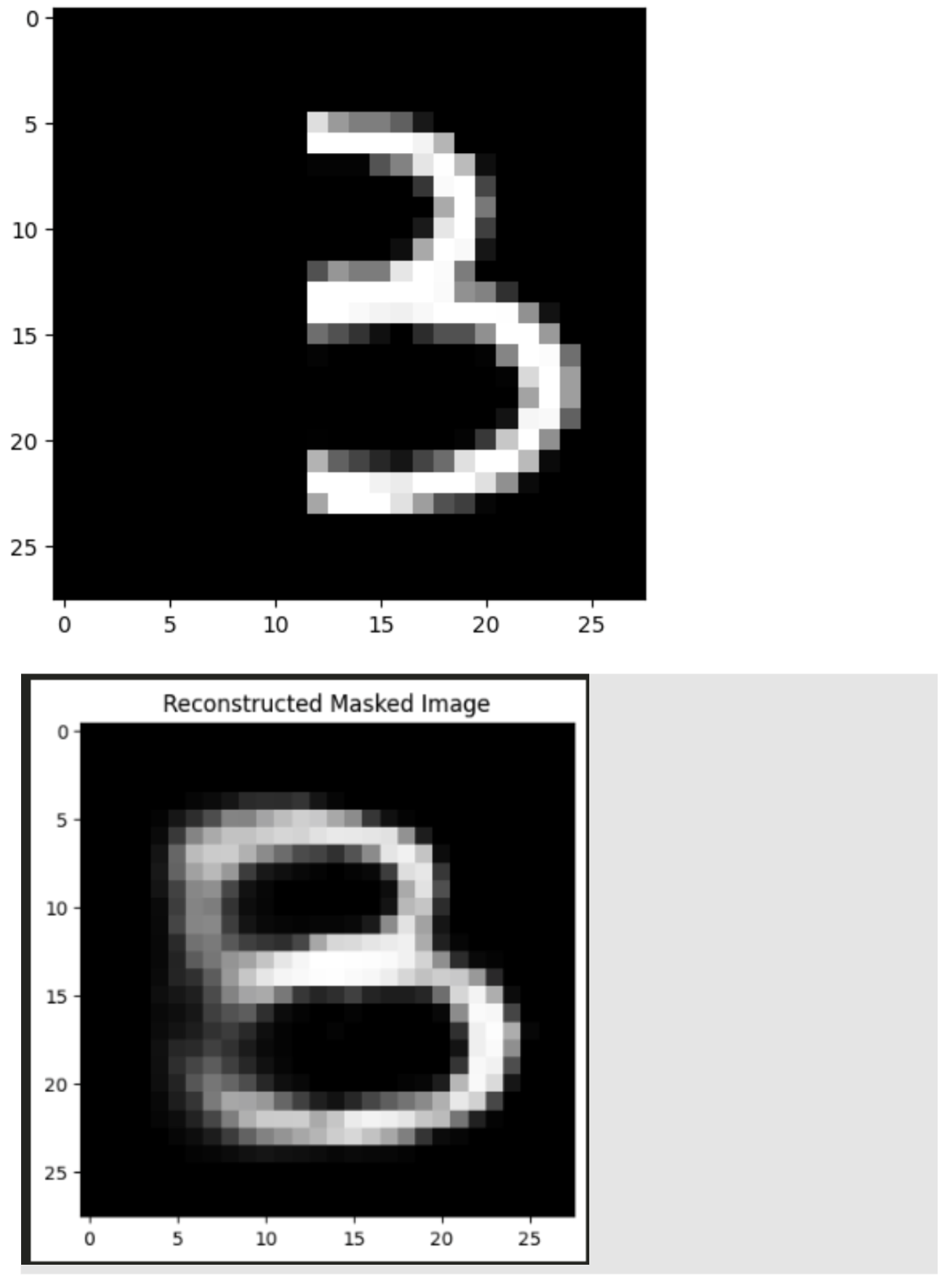
Part 1: Masked Autoencoder
What is it:
- Masked autoencoding zeros out parts of an image, and trains the autoencoder to reconstruct the original image from partially masked inputs.
The task:
- We were tasked with training a simple multi-layer perceptron model to act as an autoencoder, to reconstruct corrupted input into the correct input.
Findings:
- The MLP fails to effectively reconstruct the input image. It fails to do so because the model was trained to reconstruct a masked left half of an image, therefore, the model doesn’t fully understand that how to differentiate a 3 from an 8. This explains why the left half is less prominent – there were times during training where it correctly learned to associate a 3 with a 3, but there were times where the right half of the image looked like a 3, but happened to be an 8. Therefore our reconstruction, while wrong, and an incredibly interesting concept to think about.
- It is also a great reminder that models will only know to predict things within its learned weights and biases, and cannot go outside of this distribution.
Part 2: Sequence learning with a LSTM and RNN
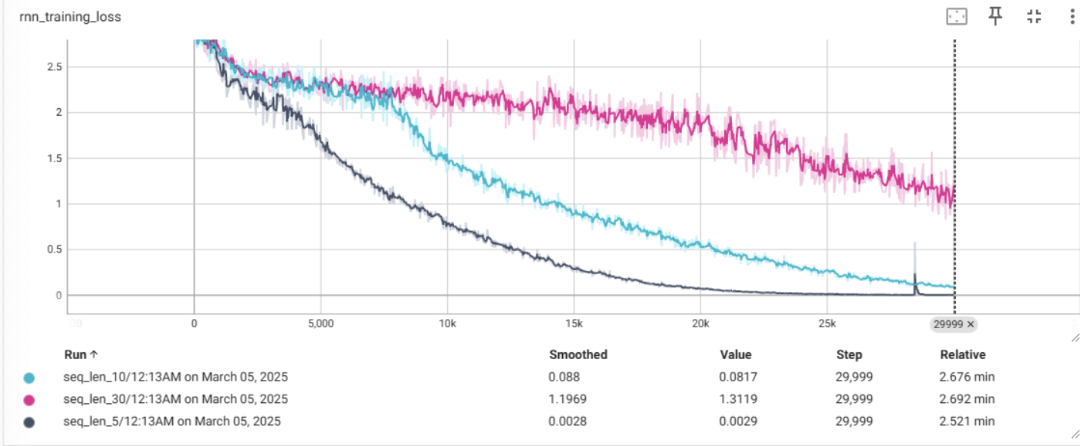
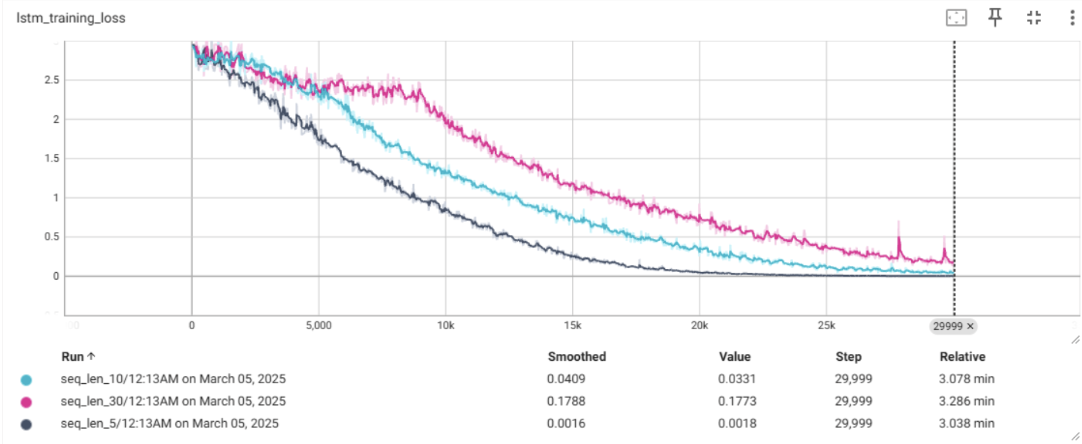
Theoretically, why would we expect an LSTM to outperform a standard RNN on problems with long sequences?
- In a traditional RNN, when weights are less than 1, as the length of the sequence increases, backpropogation would have the weights approach 0, and when the weights are greater than 1, they approach infinity. An LSTM helps mitigate against the exploding/vanishing gradients problem because they use gating mechanisms to keep gradients stable by maintaing and forgetting long term information over time.
- We example this theory with an analysis from my PyTorch solution
RNN Training Loss
LSTM Loss
Conclusion
- This example helps support the theory above, that the LSTM helps mitigate against the exploding/vanishing gradients problem as the sequence length increases.