Overview
This was a personal passion project of mine. It didn’t take very long to build (only a day), but it is something that was fun to create and was useful to my everyday life. I later stopped the project because I realized that it went against the robots.txt that I found on a site and didn’t mean to go against any regulations. So while it is no longer active, I still had a great time learning more about web scraping and how to automate things through AWS.
I am a Utah Jazz fan! However, during the school year I had a hard time finding much time to watch as many games as I wanted around the NBA. Therefore, I created this automated email solution that could keep me up-to-date about what is happening around the NBA, standings, and a more tailored description of how the Jazz are doing.
As you will see, I leveraged the services on AWS to email myself updates, every morning.
How I did it
Data collection
I wrote a Python script that lives on AWS Lambda that could be spun up whenever I needed to use it.
The information that I cared to scrape for my use-cases were:
- Stats
- News
- Schedule
- Standings
- Scores
Each of the categories I cared to scrape information from required a date to gather information from. Therefore, I pass in the string format of the previous date to each endpoint to get the correct information.
#
# Date information
#
today = datetime.now()
yesterday = today - timedelta(days=1)
yesterday_str = yesterday.strftime('%Y-%m-%d')
#
# Helper functions per category
#
scrape_stats(yesterday_str)
scrape_news(yesterday_str)
scrape_schedule(yesterday_str)
scrape_standings(yesterday_str)
scrape_scores(yesterday_str)
Each helper function works in its own way to correctly scrape the data. For reference, though, I include an example of how I used BeautifulSoup to scrape the a site for stats:
def scrape_standings(yesterday_str):
url = ###
response = requests.get(url)
#
# The structure of the data that I am saving
#
@dataclass
class Standing:
conference: str
rank: int
team: str
win_loss: str
pct: float
streak: str
standings = []
if response.status_code == 200:
content = response.text
soup = BeautifulSoup(content, 'html.parser')
conferences_tables = soup.find_all('div', class_='table-wrapper-container group-section')
#
# Storing relevant information in local variables
#
if conferences_tables:
western_conference_table = conferences_tables[0]
eastern_conference_table = conferences_tables[1]
western_conference_standings = western_conference_table.find_all('tr')
eastern_conference_standings = eastern_conference_table.find_all('tr')
#
# Going through Western conference tables
#
for i, team_row in enumerate(western_conference_standings):
if i == 0:
continue
rank_td = team_row.find('td', class_='cell-rank ffn-11')
rank = int(rank_td.get_text(strip=True)) if rank_td else None
team_td = team_row.find('a', class_='table-entity-name ff-ffc')
team_name = team_td.get_text(strip=True) if team_td else None
win_loss_td = team_row.find_all('td', class_='cell-record ff-h')
win_loss = win_loss_td[0].get_text(strip=True) if win_loss_td else None
pct_td = team_row.find_all('td', class_='cell-number ff-h')
pct = float(pct_td[0].get_text(strip=True)) if pct_td else None
streak_td = team_row.find('td', class_='cell-text ff-h')
streak = streak_td.get_text(strip=True) if streak_td else None
if rank and team_name and win_loss and pct and streak:
standings.append(Standing('West', rank, team_name, win_loss, pct, streak))
#
# Going through Eastern conference tables
#
for i, team_row in enumerate(eastern_conference_standings):
if i == 0:
continue
rank_td = team_row.find('td', class_='cell-rank ffn-11')
rank = int(rank_td.get_text(strip=True)) if rank_td else None
team_td = team_row.find('a', class_='table-entity-name ff-ffc')
team_name = team_td.get_text(strip=True) if team_td else None
win_loss_td = team_row.find_all('td', class_='cell-record ff-h')
win_loss = win_loss_td[0].get_text(strip=True) if win_loss_td else None
pct_td = team_row.find_all('td', class_='cell-number ff-h')
pct = float(pct_td[0].get_text(strip=True)) if pct_td else None
streak_td = team_row.find('td', class_='cell-text ff-h')
streak = streak_td.get_text(strip=True) if streak_td else None
if rank and team_name and win_loss and pct and streak:
standings.append(Standing('East', rank, team_name, win_loss, pct, streak))
#
# Save Jazz info to local Lambda memory /tmp
#
try:
if standings:
df = pd.DataFrame(standings)
jazz_standing = df[df['team'] == 'Jazz']
jazz_standing.to_csv(f'/tmp/nba-data/{yesterday_str}/standing.txt', sep='\t', index=False)
else:
raise ValueError
except Exception as e:
print("ERROR: ", e)
Using an LLM to create a summary for me
After I collected all of the relevant information that I wanted, I pulled all of the information into a new lambda function from the local /tmp memory.
This lambda function then utilized langchain’s ChatOpenAI method to help me connect to the correct data loaders and functions I needed for my task.
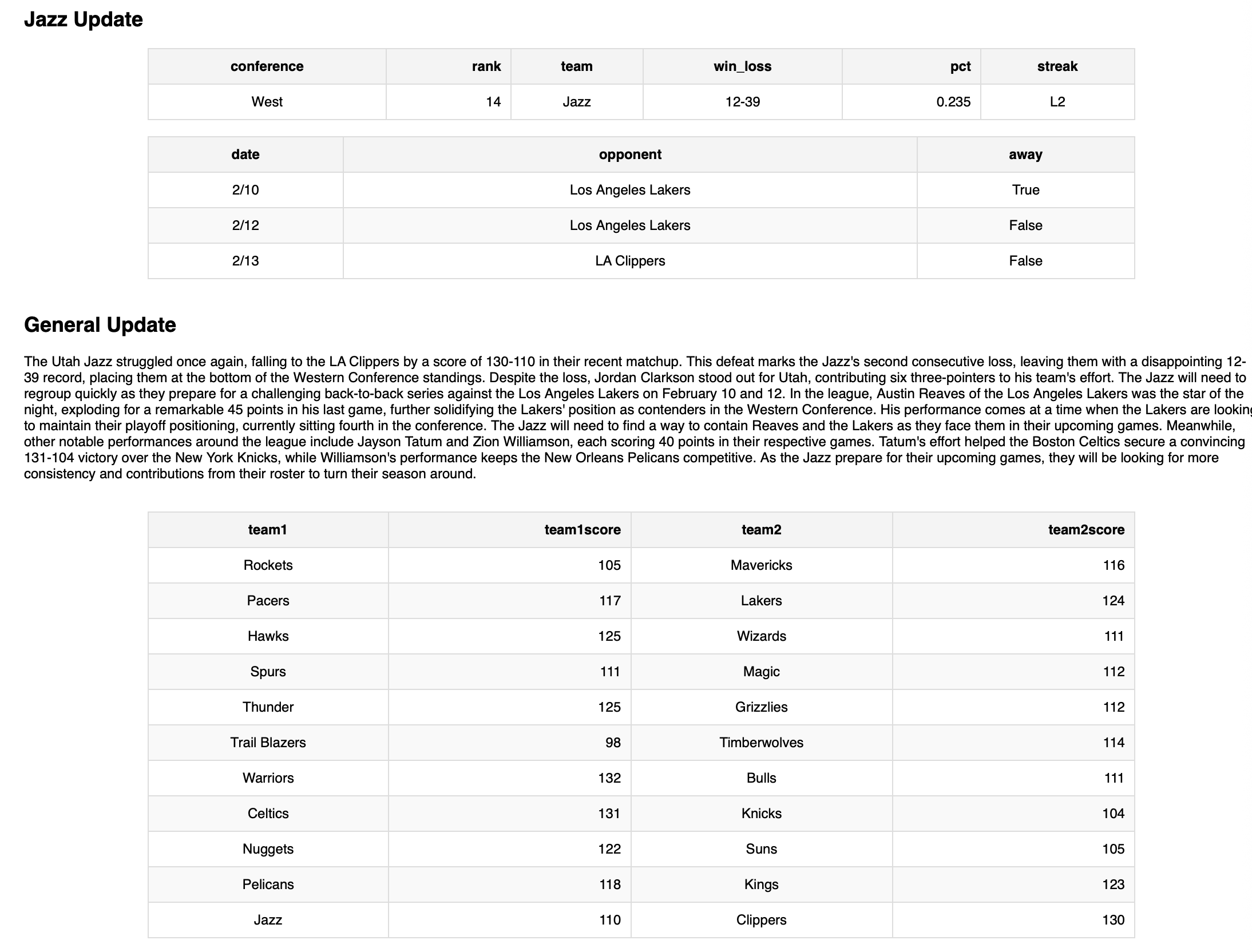
The result created a message that summarized yesterday’s nba games in a single paragraph and that emphasized the Jazz, for my own interest.
# ...
# ...
# ...
#
# Loading in all of the data collected
#
loader = DirectoryLoader('/tmp/', glob='*.txt', loader_cls=TextLoader)
docs = loader.load()
docs_content = "\n\n".join(doc.page_content for doc in docs)
llm = ChatOpenAI(model='gpt-4o-mini')
#
# Creating a good prompt that explains my goal
#
prompt = f"""
You are an NBA writer.
Write a three-paragraph NBA update based only on the information provided.
Use things from the <context> I give you, like news articles to summarize key stories,
and incorporate scores to highlight recent games.
Keep in mind that I am a Jazz fan, so I care more about Jazz info when they do play.
Ensure your summary is concise and accurate.
<context>
{docs_content}
Your response:
"""
response = llm.invoke(prompt)
paragraph_summary = response.content
# Getting relevant info
standing_content = generate_content('/tmp/standing.txt')
upcoming_content = generate_content('/tmp/upcoming.txt')
scores_content = generate_content('/tmp/scores.txt')
stats_content = generate_content('/tmp/stats.txt')
ses = boto3.client('ses', region_name='us-east-2')
subject = "Daily NBA Update!"
#
# Sending an email to myself in a format that I created with HTML and CSS
#
html_body = f"""
<html>
<head>
<style>
table {{
border-collapse: collapse;
margin: 0 auto;
width: 80%;
}}
th, td {{
border: 1px solid #ddd;
padding: 8px;
text-align: center;
}}
th {{
background-color: #f4f4f4;
font-weight: bold;
}}
tr:nth-child(even) {{ background-color: #f9f9f9; }}
tr:hover {{ background-color: #f1f1f1; }}
</style>
</head>
<body>
<h2>Jazz Update</h2>
<div style='text-align: center;'>
{standing_content}
</div>
<br/>
<div style='text-align: center;'>
{upcoming_content}
</div>
<br />
<h2>General Update</h2>
<p>
{paragraph_summary}
</p>
<br />
<div style='text-align: center;'>
{scores_content}
</div>
</body>
</html>
"""
text_body = "Hello from AWS Lambda! This email was sent using Amazon SES with a plain text body."
try:
response = ses.send_email(
Source='pmcslarrow@icloud.com',
Destination={
'ToAddresses': ['pmcslarrow@icloud.com'],
},
Message={
'Subject': {
'Data': subject
},
'Body': {
'Text': {
'Data': text_body
},
'Html': {
'Data': html_body
}
}
}
)
except Exception as e:
print("Failed to send email...", e)
Final Result