Code
- The code can be found within this PDF
- Can also be found within this repo at static/images/wide_and_deep/wide_and_deep.pdf
Overview
This is a passion project I’ve been working on to deepen my understanding of recommender systems in my free time. While I’ve previously implemented simpler methods—such as matrix factorization or with basic content-based filtering, this project is my attempt to implement a more elegant solution inspired by this paper.
Architecture Summary
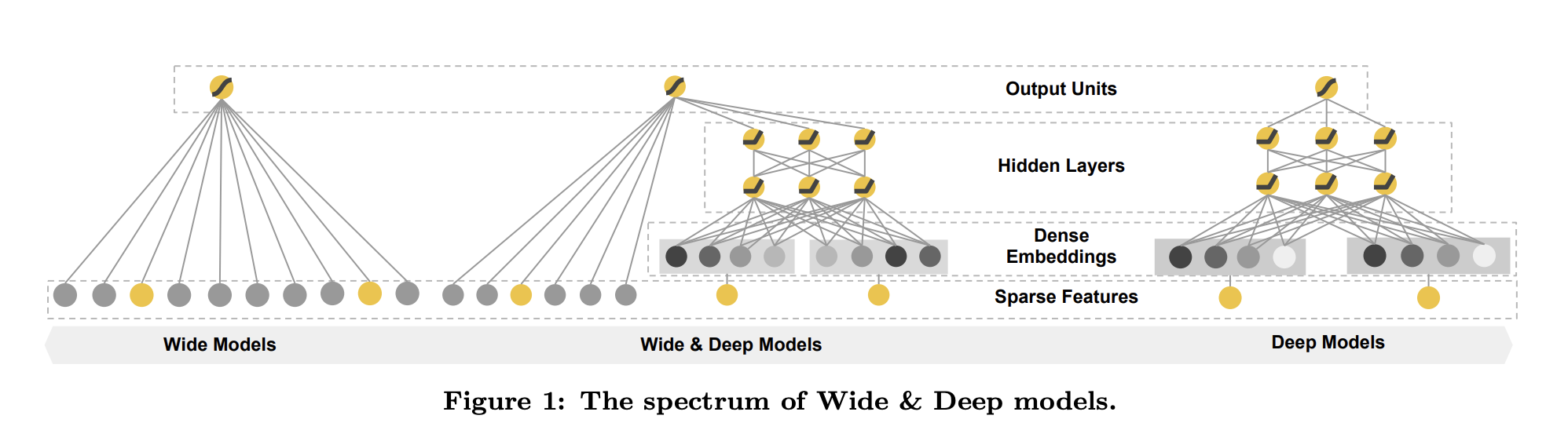
The model processes inputs related to user–item pairs and leverages two components:
- Wide component: uses cross-products to memorize feature interactions.
- Deep component: employs a neural network to generalize to unseen feature combinations.
The outputs of these two components are combined and updated jointly, with the goal of predicting whether a user would like a given item based on an explicit rating.
While the ratings in the dataset are between 0 and 5, I simplified the rating to be 1 for ratings >= 4 and 0 otherwise. With a binary goal in mind, we are able to train our model using binary cross-entropy loss (BCE).
Feature Engineering
The paper mentioned the utilization of cross-embeddings; however, I chose a different approach for this implementation.
- For the wide (linear) component, I transformed the continuous variables (
user_id,book_id) into one-hot embeddings. - For the deep component, I followed the paper’s suggestion and used an embedding layer to capture more complex relationships across features (
user_id,book_id, andgenre).
Summary
While the model may not have captured much signal (or may have overfit the training set), I used AUC to evaluate its ability to distinguish between positive and negative classes on the test set. With random guessing, the AUC would be around 0.5, regardless of the class distribution.
In this dataset, about 68% of the examples were positive, and the model still achieved fair performance given the limited feature set (user ID, book ID, and a single genre). With additional metadata, the model would likely have identified stronger patterns between features and labels.
Overall, this can be considered a successful result.